Best Practices for Developing Java Applications with TiDB
This document introduces the best practice for developing Java applications to better use TiDB. Based on some common Java application components that interact with the backend TiDB database, this document also provides the solutions to commonly encountered issues during development.
Database-related components in Java applications
Common components that interact with the TiDB database in Java applications include:
- Network protocol: A client interacts with a TiDB server via the standard MySQL protocol.
- JDBC API and JDBC drivers: Java applications usually use the standard JDBC (Java Database Connectivity) API to access a database. To connect to TiDB, you can use a JDBC driver that implements the MySQL protocol via the JDBC API. Such common JDBC drivers for MySQL include MySQL Connector/J and MariaDB Connector/J.
- Database connection pool: To reduce the overhead of creating a connection each time it is requested, applications usually use a connection pool to cache and reuse connections. JDBC DataSource defines a connection pool API. You can choose from different open-source connection pool implementations as needed.
- Data access framework: Applications usually use a data access framework such as MyBatis and Hibernate to further simplify and manage the database access operations.
- Application implementation: The application logic controls when to send what commands to the database. Some applications use Spring Transaction aspects to manage transactions' start and commit logics.
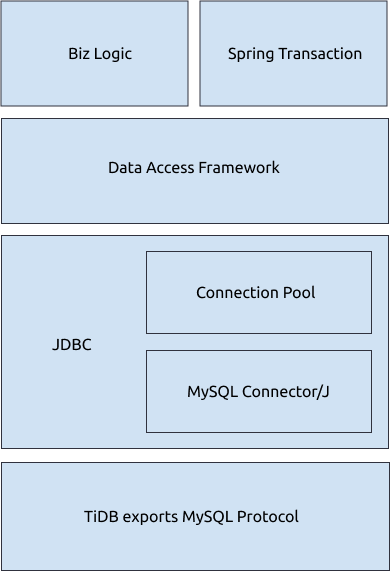
From the above diagram, you can see that a Java application might do the following things:
- Implement the MySQL protocol via the JDBC API to interact with TiDB.
- Get a persistent connection from the connection pool.
- Use a data access framework such as MyBatis to generate and execute SQL statements.
- Use Spring Transaction to automatically start or stop a transaction.
The rest of this document describes the issues and their solutions when you develop a Java application using the above components.
JDBC
Java applications can be encapsulated with various frameworks. In most of the frameworks, JDBC API is called on the bottommost level to interact with the database server. For JDBC, it is recommended that you focus on the following things:
- JDBC API usage choice
- API Implementer's parameter configuration
JDBC API
For JDBC API usage, see JDBC official tutorial. This section covers the usage of several important APIs.
Use Prepare API
For OLTP (Online Transactional Processing) scenarios, the SQL statements sent by the program to the database are several types that can be exhausted after removing parameter changes. Therefore, it is recommended to use Prepared Statements instead of regular execution from a text file and reuse Prepared Statements to execute directly. This avoids the overhead of repeatedly parsing and generating SQL execution plans in TiDB.
At present, most upper-level frameworks call the Prepare API for SQL execution. If you use the JDBC API directly for development, pay attention to choosing the Prepare API.
In addition, with the default implementation of MySQL Connector/J, only client-side statements are preprocessed, and the statements are sent to the server in a text file after ? is replaced on the client. Therefore, in addition to using the Prepare API, you also need to configure useServerPrepStmts = true in JDBC connection parameters before you perform statement preprocessing on the TiDB server. For detailed parameter configuration, see MySQL JDBC parameters.
Use Batch API
For batch inserts, you can use the addBatch/executeBatch API. The addBatch() method is used to cache multiple SQL statements first on the client, and then send them to the database server together when calling the executeBatch method.
Use StreamingResult to get the execution result
In most scenarios, to improve execution efficiency, JDBC obtains query results in advance and save them in client memory by default. But when the query returns a super large result set, the client often wants the database server to reduce the number of records returned at a time, and waits until the client's memory is ready and it requests for the next batch.
Usually, there are two kinds of processing methods in JDBC:
Set
FetchSizetoInteger.MIN_VALUEto ensure that the client does not cache. The client will read the execution result from the network connection throughStreamingResult.When the client uses the streaming read method, it needs to finish reading or close
resultsetbefore continuing to use the statement to make a query. Otherwise, the errorNo statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.is returned.To avoid such an error in queries before the client finishes reading or closes
resultset, you can add theclobberStreamingResults=trueparameter in the URL. Then,resultsetis automatically closed but the result set to be read in the previous streaming query is lost.To use Cursor Fetch, first set
FetchSizeas a positive integer and configureuseCursorFetch=truein the JDBC URL.
TiDB supports both methods, but it is preferred that you use the first method, because it is a simpler implementation and has a better execution efficiency.
MySQL JDBC parameters
JDBC usually provides implementation-related configurations in the form of JDBC URL parameters. This section introduces MySQL Connector/J's parameter configurations (If you use MariaDB, see MariaDB's parameter configurations). Because this document cannot cover all configuration items, it mainly focuses on several parameters that might affect performance.
Prepare-related parameters
This section introduces parameters related to Prepare.
useServerPrepStmts
useServerPrepStmts is set to false by default, that is, even if you use the Prepare API, the "prepare" operation will be done only on the client. To avoid the parsing overhead of the server, if the same SQL statement uses the Prepare API multiple times, it is recommended to set this configuration to true.
To verify that this setting already takes effect, you can do:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > CPS By Instance.
- If
COM_QUERYis replaced byCOM_STMT_EXECUTEorCOM_STMT_PREPAREin the request, it means this setting already takes effect.
cachePrepStmts
Although useServerPrepStmts=true allows the server to execute Prepared Statements, by default, the client closes the Prepared Statements after each execution and does not reuse them. This means that the "prepare" operation is not even as efficient as text file execution. To solve this, it is recommended that after setting useServerPrepStmts=true, you should also configure cachePrepStmts=true. This allows the client to cache Prepared Statements.
To verify that this setting already takes effect, you can do:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > CPS By Instance.
- If the number of
COM_STMT_EXECUTEin the request is far more than the number ofCOM_STMT_PREPARE, it means this setting already takes effect.
In addition, configuring useConfigs=maxPerformance will configure multiple parameters at the same time, including cachePrepStmts=true.
prepStmtCacheSqlLimit
After configuring cachePrepStmts, also pay attention to the prepStmtCacheSqlLimit configuration (the default value is 256). This configuration controls the maximum length of the Prepared Statements cached on the client.
The Prepared Statements that exceed this maximum length will not be cached, so they cannot be reused. In this case, you may consider increasing the value of this configuration depending on the actual SQL length of the application.
You need to check whether this setting is too small if you:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > CPS By Instance.
- And find that
cachePrepStmts=truehas been configured, butCOM_STMT_PREPAREis still mostly equal toCOM_STMT_EXECUTEandCOM_STMT_CLOSEexists.
prepStmtCacheSize
prepStmtCacheSize controls the number of cached Prepared Statements (the default value is 25). If your application requires "preparing" many types of SQL statements and wants to reuse Prepared Statements, you can increase this value.
To verify that this setting already takes effect, you can do:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > CPS By Instance.
- If the number of
COM_STMT_EXECUTEin the request is far more than the number ofCOM_STMT_PREPARE, it means this setting already takes effect.
Batch-related parameters
While processing batch writes, it is recommended to configure rewriteBatchedStatements=true. After using addBatch() or executeBatch(), JDBC still sends SQL one by one by default, for example:
pstmt = prepare("insert into t (a) values(?)");
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
Although Batch methods are used, the SQL statements sent to TiDB are still individual INSERT statements:
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
But if you set rewriteBatchedStatements=true, the SQL statements sent to TiDB will be a single INSERT statement:
insert into t(a) values(10),(11),(12);
Note that the rewrite of the INSERT statements is to concatenate the values after multiple "values" keywords into a whole SQL statement. If the INSERT statements have other differences, they cannot be rewritten, for example:
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
The above INSERT statements cannot be rewritten into one statement. But if you change the three statements into the following ones:
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
Then they meet the rewrite requirement. The above INSERT statements will be rewritten into the following one statement:
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
If there are three or more updates during the batch update, the SQL statements will be rewritten and sent as multiple queries. This effectively reduces the client-to-server request overhead, but the side effect is that a larger SQL statement is generated. For example:
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
In addition, because of a client bug, if you want to configure rewriteBatchedStatements=true and useServerPrepStmts=true during batch update, it is recommended that you also configure the allowMultiQueries=true parameter to avoid this bug.
Integrate parameters
Through monitoring, you might notice that although the application only performs INSERT operations to the TiDB cluster, there are a lot of redundant SELECT statements. Usually this happens because JDBC sends some SQL statements to query the settings, for example, select @@session.transaction_read_only. These SQL statements are useless for TiDB, so it is recommended that you configure useConfigs=maxPerformance to avoid extra overhead.
useConfigs=maxPerformance includes a group of configurations. To get the detailed configurations in MySQL Connector/J 8.0 and those in MySQL Connector/J 5.1, see mysql-connector-j 8.0 and mysql-connector-j 5.1 respectively.
After it is configured, you can check the monitoring to see a decreased number of SELECT statements.
Timeout-related parameters
TiDB provides two MySQL-compatible parameters that controls the timeout: wait_timeout and max_execution_time. These two parameters respectively control the connection idle timeout with the Java application and the timeout of the SQL execution in the connection; that is to say, these parameters control the longest idle time and the longest busy time for the connection between TiDB and the Java application. The default value of both parameters is 0, which by default allows the connection to be infinitely idle and infinitely busy (an infinite duration for one SQL statement to execute).
However, in an actual production environment, idle connections and SQL statements with excessively long execution time negatively affect databases and applications. To avoid idle connections and SQL statements that are executed for too long, you can configure these two parameters in your application's connection string. For example, set sessionVariables=wait_timeout=3600 (1 hour) and sessionVariables=max_execution_time=300000 (5 minutes).
Connection pool
Building TiDB (MySQL) connections is relatively expensive (for OLTP scenarios at least), because in addition to building a TCP connection, connection authentication is also required. Therefore, the client usually saves the TiDB (MySQL) connections to the connection pool for reuse.
Java has many connection pool implementations such as HikariCP, tomcat-jdbc, druid, c3p0, and dbcp. TiDB does not limit which connection pool you use, so you can choose whichever you like for your application.
Configure the number of connections
It is a common practice that the connection pool size is well adjusted according to the application's own needs. Take HikariCP as an example:
maximumPoolSize: The maximum number of connections in the connection pool. If this value is too large, TiDB consumes resources to maintain useless connections. If this value is too small, the application gets slow connections. So configure this value for your own good. For details, see About Pool Sizing.minimumIdle: The minimum number of idle connections in the connection pool. It is mainly used to reserve some connections to respond to sudden requests when the application is idle. You can also configure it according to your application needs.
The application needs to return the connection after finishing using it. It is also recommended that the application use the corresponding connection pool monitoring (such as metricRegistry) to locate the connection pool issue in time.
Probe configuration
The connection pool maintains persistent connections from clients to TiDB as follows:
- Before v5.4, TiDB does not proactively close client connections by default (unless an error is reported).
- Starting from v5.4, TiDB automatically closes client connections after
28800seconds (this is,8hours) of inactivity by default. You can control this timeout setting using the TiDB and MySQL compatiblewait_timeoutvariable. For more information, see JDBC Query Timeout.
Moreover, there might be network proxies such as LVS or HAProxy between clients and TiDB. These proxies typically proactively clean up connections after a specific idle period (determined by the proxy's idle configuration). In addition to monitoring the proxy's idle configuration, connection pools also need to maintain or probe connections for keep-alive.
If you often see the following error in your Java application:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
If n in n milliseconds ago is 0 or a very small value, it is usually because the executed SQL operation causes TiDB to exit abnormally. To find the cause, it is recommended to check the TiDB stderr log.
If n is a very large value (such as 3600000 in the above example), it is likely that this connection was idle for a long time and then closed by the intermediate proxy. The usual solution is to increase the value of the proxy's idle configuration and allow the connection pool to:
- Check whether the connection is available before using the connection every time
- Regularly check whether the connection is available using a separate thread.
- Send a test query regularly to keep alive connections
Different connection pool implementations might support one or more of the above methods. You can check your connection pool documentation to find the corresponding configuration.
Data access framework
Applications often use some kind of data access framework to simplify database access.
MyBatis
MyBatis is a popular Java data access framework. It is mainly used to manage SQL queries and complete the mapping between result sets and Java objects. MyBatis is highly compatible with TiDB. MyBatis rarely has problems based on its historical issues.
Here this document mainly focuses on the following configurations.
Mapper parameters
MyBatis Mapper supports two parameters:
select 1 from t where id = #{param1}will be converted toselect 1 from t where id =?as a Prepared Statement and be "prepared", and the actual parameter will be used for reuse. You can get the best performance when using this parameter with the previously mentioned Prepare connection parameters.select 1 from t where id = ${param2}will be replaced withselect 1 from t where id = 1as a text file and be executed. If this statement is replaced with different parameters and is executed, MyBatis will send different requests for "preparing" the statements to TiDB. This might cause TiDB to cache a large number of Prepared Statements, and executing SQL operations this way has injection security risks.
Dynamic SQL Batch
To support the automatic rewriting of multiple INSERT statements into the form of insert ... values(...), (...), ..., in addition to configuring rewriteBatchedStatements=true in JDBC as mentioned before, MyBatis can also use dynamic SQL to semi-automatically generate batch inserts. Take the following mapper as an example:
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
This mapper generates an insert on duplicate key update statement. The number of (?,?,?) following "values" is determined by the number of passed lists. Its final effect is similar to using rewriteBatchStatements=true, which also effectively reduces communication overhead between the client and TiDB.
As mentioned before, you also need to note that the Prepared Statements will not be cached after their maximum length exceeds the value of prepStmtCacheSqlLimit.
Streaming result
A previous section introduces how to stream read execution results in JDBC. In addition to the corresponding configurations of JDBC, if you want to read a super large result set in MyBatis, you also need to note that:
- You can set
fetchSizefor a single SQL statement in the mapper configuration (see the previous code block). Its effect is equivalent to callingsetFetchSizein JDBC. - You can use the query interface with
ResultHandlerto avoid getting the entire result set at once. - You can use the
Cursorclass for stream reading.
If you configure mappings using XML, you can stream read results by configuring fetchSize="-2147483648"(Integer.MIN_VALUE) in the mapping's <select> section.
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
If you configure mappings using code, you can add the @Options(fetchSize = Integer.MIN_VALUE) annotation and keep the type of results as Cursor so that the SQL results can be read in streaming.
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
ExecutorType
You can choose ExecutorType during openSession. MyBatis supports three types of executors:
- Simple: The Prepared Statements are called to JDBC for each execution (if the JDBC configuration item
cachePrepStmtsis enabled, repeated Prepared Statements will be reused) - Reuse: The Prepared Statements are cached in
executor, so that you can reduce duplicate calls for Prepared Statements without using the JDBCcachePrepStmts - Batch: Each update operation (
INSERT/DELETE/UPDATE) will first be added to the batch, and will be executed until the transaction commits or aSELECTquery is performed. IfrewriteBatchStatementsis enabled in the JDBC layer, it will try to rewrite the statements. If not, the statements will be sent one by one.
Usually, the default value of ExecutorType is Simple. You need to change ExecutorType when calling openSession. If it is the batch execution, you might find that in a transaction the UPDATE or INSERT statements are executed pretty fast, but it is slower when reading data or committing the transaction. This is actually normal, so you need to note this when troubleshooting slow SQL queries.
Spring Transaction
In the real world, applications might use Spring Transaction and AOP aspects to start and stop transactions.
By adding the @Transactional annotation to the method definition, AOP starts the transaction before the method is called, and commits the transaction before the method returns the result. If your application has a similar need, you can find @Transactional in code to determine when the transaction is started and closed.
Pay attention to a special case of embedding. If it occurs, Spring will behave differently based on the Propagation configuration.
Misc
This section introduces some useful tools for Java to help you troubleshoot issues.
Troubleshooting tools
Using the powerful troubleshooting tools of JVM is recommended when an issue occurs in your Java application and you do not know the application logic. Here are a few common tools:
jstack
jstack is similar to pprof/goroutine in Go, which can easily troubleshoot the process stuck issue.
By executing jstack pid, you can output the IDs and stack information of all threads in the target process. By default, only the Java stack is output. If you want to output the C++ stack in the JVM at the same time, add the -m option.
By using jstack multiple times, you can easily locate the stuck issue (for example, a slow query from application's view due to using Batch ExecutorType in Mybatis) or the application deadlock issue (for example, the application does not send any SQL statement because it is preempting a lock before sending it).
In addition, top -p $ PID -H or Java swiss knife are common methods to view the thread ID. Also, to locate the issue of "a thread occupies a lot of CPU resources and I don't know what it is executing", do the following steps:
- Use
printf "%x\n" pidto convert the thread ID to hexadecimal. - Go to the jstack output to find the stack information of the corresponding thread.
jmap & mat
Unlike pprof/heap in Go, jmap dumps the memory snapshot of the entire process (in Go, it is the sampling of the distributor), and then the snapshot can be analyzed by another tool mat.
Through mat, you can see the associated information and attributes of all objects in the process, and you can also observe the running status of the thread. For example, you can use mat to find out how many MySQL connection objects exist in the current application, and what is the address and status information of each connection object.
Note that mat only handles reachable objects by default. If you want to troubleshoot young GC issues, you can adjust mat configuration to view unreachable objects. In addition, for investigating the memory allocation of young GC issues (or a large number of short-lived objects), using Java Flight Recorder is more convenient.
trace
Online applications usually do not support modifying the code, but it is often desired that dynamic instrumentation is performed in Java to locate issues. Therefore, using btrace or arthas trace is a good option. They can dynamically insert trace code without restarting the application process.
Flame graph
Obtaining flame graphs in Java applications is tedious. For details, see Java Flame Graphs Introduction: Fire For Everyone!.
Conclusion
Based on commonly used Java components that interact with databases, this document describes the common problems and solutions for developing Java applications with TiDB. TiDB is highly compatible with the MySQL protocol, so most of the best practices for MySQL-based Java applications also apply to TiDB.
Join us at TiDB Community slack channel, and share with broad TiDB user group about your experience or problems when you develop Java applications with TiDB.